
УДК 004.9:004.65:005
Автоматизация соблюдения требований нормативных документов
при проектировании ИМ через коды Классификатора строительной информации (КСИ)
Аннотация: Статья посвящена одной из задач в области проектирования — автоматизации соблюдения положений нормативных документов. Для ее решения необходимо, во-первых, преобразовать нормативные тексты в исполняемый программный код, во-вторых, создать качественные и детализированные информационные модели (ИМ/ЦИМ) и, в-третьих, сопоставить информацию об объектах модели с текстом нормативных требований — например, через Классификатор строительной информации (КСИ). Все это невозможно без использования интеллектуальных методов обработки нормативных текстов. Такие методы разрабатываются компанией «Нанософт» в рамках направления NSR Specification.
Ключевые слова: машиночитаемость, контент, машинопонимаемость, требование, семантический анализ, онтологии, алгоритмы машинного обучения, нейронные сети, информационная модель (ИМ), технологии информационного моделирования (ТИМ), SMART-стандарт, объект капитального строительства (ОКС), КСИ.
Технологии информационного моделирования — зло или благо?
В далеком уже 2016 году
В теории внедрение ТИМ в жизненный цикл ОКС, как и любая инновационная технология, должно было обеспечить:
- сокращение сроков выполнения проекта;
- снижение издержек на выполнение проекта;
- улучшение качества документации;
- соблюдение требований безопасности возводимых ОКС.
На практике же и по сей день разработка информационной модели является особым этапом проектирования, выполнение которого требует увеличения сроков и трудозатрат. Поэтому зачастую ИМ создается постфактум, на основе классической проектной документации. И эта модель отличается недостаточной детализацией графического и информационного наполнения.
Фактически единственный практический эффект от таких ИМ сводится к возможности выполнить базовые проверки на геометрические коллизии архитектурных, конструктивных и инженерных систем. Такая проверка действительно может способствовать сокращению издержек на этапе строительства, возникающих из-за необходимости исправлять проектные ошибки в процессе возведения объекта. Но только при условии соответствия ИМ и документации, используемой на стройке.
В то же время считалось, что потенциал ТИМ будет более осязаемым. Он должен был заключаться, например, в возможности проводить экспертизу ИМ на соответствие требованиям нормативных документов. А для этого необходимо, чтобы в модели присутствовала проверяемая информация.
Иными словами, в настоящий момент имеет место своеобразный замкнутый круг: чтобы применение технологии информационного моделирования приносило ощутимый практический эффект, нужны качественные, детализированные информационные модели (ИМ/ЦИМ), делать которые сейчас мало кто может себе позволить из-за недостатка практического эффекта.
Мы, компания «Нанософт», разработчик отечественной САПР-системы и BIM-приложений, предполагаем, что выйти из этого круга можно только с помощью комплексного подхода.
С одной стороны, необходимо создавать инструменты автоматизации проектирования за счет технологий информационного моделирования. С другой — необходимо предпринять шаги по преобразованию нормативов и стандартов РФ в машинопонимаемый формат либо в виде исполняемого программного кода, либо в виде онтологий или в любой другой формат, воспринимаемый системами автоматизированного проектирования, чтобы повысить уровень его автоматизации.
Для достижения означенных целей открыто бизнес-направление NSR Specification, в рамках которого создаются продукты для разработки машиночитаемых и машинопонимаемых требований и реализуются пилотные проекты по автоматизации экспертизы ИМ. Дальнейшее развитие — разработка средств автоматизации самого процесса проектирования в соответствии с требованиями российских норм и стандартов, но для этого сперва надо научиться проверять ИМ и понять, какой должна быть ИМ, которую можно проверить.
Эволюция стандартизации в деле
Вопрос переработки нормативных документов в качественно новый вид, способный автоматизировать производственные процессы, уже давно изучали на Западе. Наибольшее распространение получила схема развития стандартизации по классификации ИСО/МЭК (рисунок 1), которая впервые ввела в обиход термин SMART-стандарт 1.

Иными словами, для того чтобы обычный человекочитаемый Свод правил (СП) превратить в сервис будущего, необходимо:
- отсканировать документ;
- распознать текст;
- структурировать документ, выделив требования 2;
- создать базу требований из нескольких источников;
- проанализировать выделенные требования, определив роли и связи слов.
После такой обработки мы получаем то, что в терминологии ISO называется машинопонимаемым контентом 3, который можно использовать для автоматизации производственных процессов.
Обращаем внимание читателя на термины машиночитаемого документа и машиночитаемого контента, которые также используются в рассматриваемой схеме. Примечательно здесь то, что машиночитаемость не наделяется высшими смыслами. Документ с распознанным структурированным текстом — уже машиночитаем. А вот если самостоятельные структурные единицы множества документов выгружены в одну базу и знают свои связи друг с другом в настоящем, прошлом и будущем — это уже можно назвать «машиночитаемым контентом» 4.
На основе этой схемы бизнес-направление NSR Specification сформировало перечень этапов, которые легли в основу разрабатываемых решений. Сканирование и распознавание текста, к счастью, можно было опустить, поскольку для наших целей мы решили ограничиться основными нормами и стандартами, используемыми при проектировании (СП и ГОСТ), а они уже были оцифрованы. Оставалось самое важное. На первом этапе — выделение требований в структуре документов и определение связей требований для создания базы с машиночитаемым контентом. Для создания связей между требованиями решено было использовать систему классификации, принятую в строительной области: Классификатор строительной информации (КСИ). На втором этапе предполагалось с помощью семантического анализа переводить требования в машинопонимаемый вид.
Но давайте обо всем по порядку.
Как создать машиночитаемый контент
Если рассматривать укрупненно, есть два пути обработки текста нормативных документов и создания машиночитаемого формата: ручной и автоматизированный.
Ручная разметка хоть и позволяет применять гибкие методики, но все же недостаточно эффективна из-за объема данных и постоянного изменения документов в области технического регулирования. Поэтому нужна автоматизация.
В первую очередь решено было рассмотреть зарубежные подходы к решению аналогичной проблемы.
Наибольший интерес вызвал отчет рабочей группы buildingSMART Regulatory Room [2], где представлен обзор форматов обмена (exchange formats), обеспечивающих взаимодействие специализированного программного обеспечения с содержанием законов, требований и рекомендаций (RRR).
Например: 1) RASE; 2) Ifc Constraint; 3) NLP и многие другие форматы. Однако сами авторы признали, что на данный момент не существует общепризнанного представления требований, что может снижать эффективность цифрового аспекта индустрии и привлекательность для покупателей.
Кроме того, в разных источниках много внимания уделялось применению методов обработки естественного языка (NLP) для строительных стандартов и нормативов, так в статьях:
- «A RMM Based Word Segmentation Method for Chinese Design Specifications of Building Stairs», J. Zhang et al., 2018 [3] была описана сегментация слов в китайских строительно-проектировочных документах с целью распознавания сущностей и последующей разработки графа знаний;
- «Approach to capturing design requirements from the existing architectural documents using natural language processing technique», J. Y. Song et al., 2018 [4] рассказано о семантическом анализе с использованием модели word2vec для представления документов;
- «A clustering approach for analyzing the computability of building code requirements», R. Zhang & El-Gohary, 2018 [5] требования строительного кодекса кластеризуются по семи категориям, фрагменты аннотируются элементами семантической информации и языком Вычислимость кластеров определяется в зависимости от требуемых времени и разметки.
По результатам анализа были выявлены ограничения всех подходов:
- преимущественно ручная разметка;
- словари и онтологии зависят от предметной области;
- шаблоны настраиваются под конкретный язык (в основном английский, который является аналитическим языком, в отличие от синтетического русского; есть разработки для китайского и корейского языков);
- ориентированы на западные структуры данных стандартов.
Перечисленные факторы делали невозможным или, как минимум, неэффективным использование зарубежного опыта. Необходимо было разработать свое решение, учитывающее особенности отечественных норм и стандартов:
- неформализованность требований;
- отсутствие четкой структуры требований по абзацам;
- вольная терминология;
- опечатки;
- противоречия.
Наиболее перспективными в задаче формализации требований оказались семантические технологии. Безусловным их преимуществом является то, что они обеспечивают возможность логического вывода, что в свою очередь позволяет произвести автоматическую генерацию производных правил и автоматическую проверку базы правил на непротиворечивость.
По итогам анализа предметной области автоматизированного проектирования зданий и сооружений в части формализации и использования нормативных требований было решено использовать в качестве машиночитаемого формата описания требований онтологическую модель. Была разработана укрупненная дорожная карта проекта в целом (рисунок 2).

Важным этапом проекта NSR Specification стал анализ применимости существующих классификаторов (КСИ и IFC) для разработки онтологической модели требований, в ходе которого установлено, что:
- КСИ не предоставляет форматов для описания требований, но его можно использовать в качестве классификатора для элементов, входящих в требование;
- модель данных IFC также не предоставляет отдельных сущностей для описания самих требований.
Поэтому было принято решение разработать собственную онтологию, содержащую класс для требований и отношения для характеристик требований, которую можно использовать для автоматизации назначения требованиям кодов КСИ.
Был создан алгоритм автоматического выделения границ требований (сегментации) в тексте. В результате испытаний тестовых пайплайнов предпочтительным оказался пайплайн сегментации посредством кластеризации с использованием метаобучения, который показал точность в 97%.
В итоге получен инструмент, автоматизирующий обработку нормативного текста (Модуль семантической обработки NSR Specification), который используется командой экспертов при создании базы машиночитаемых требований для «Подсистемы требований NSR Specification».
Данный продукт является веб-ресурсом, доступ пользователей осуществляется в режиме онлайн. Главная задача подсистемы требований — упростить поиск и анализ информации из нормативных источников и предоставить справку о кодах КСИ, подходящих к тексту требования.
Модуль семантической обработки NSR Specification кончено же не является волшебной палочкой. До сих пор нерешенными остаются вопросы обработки табличных данных и изображений. Но с учетом уже освоенных технологий хочется надеяться, что у нас есть все шансы на успех.
Машинопонимаемые требования
Для создания машинопонимаемых требований путь пока только один: ручной семантический анализ, в ходе которого можно одновременно получить материалы для тестирования экспертизы ИМ и базу примеров для создания алгоритмов машинного обучения, что в будущем позволит автоматизировать разметку.
В ходе обработки требований экспертами устанавливаются семантические роли, семантические типы, связи слов, а смысловые единицы требования сопоставляются с кодами КСИ (рисунок 3).
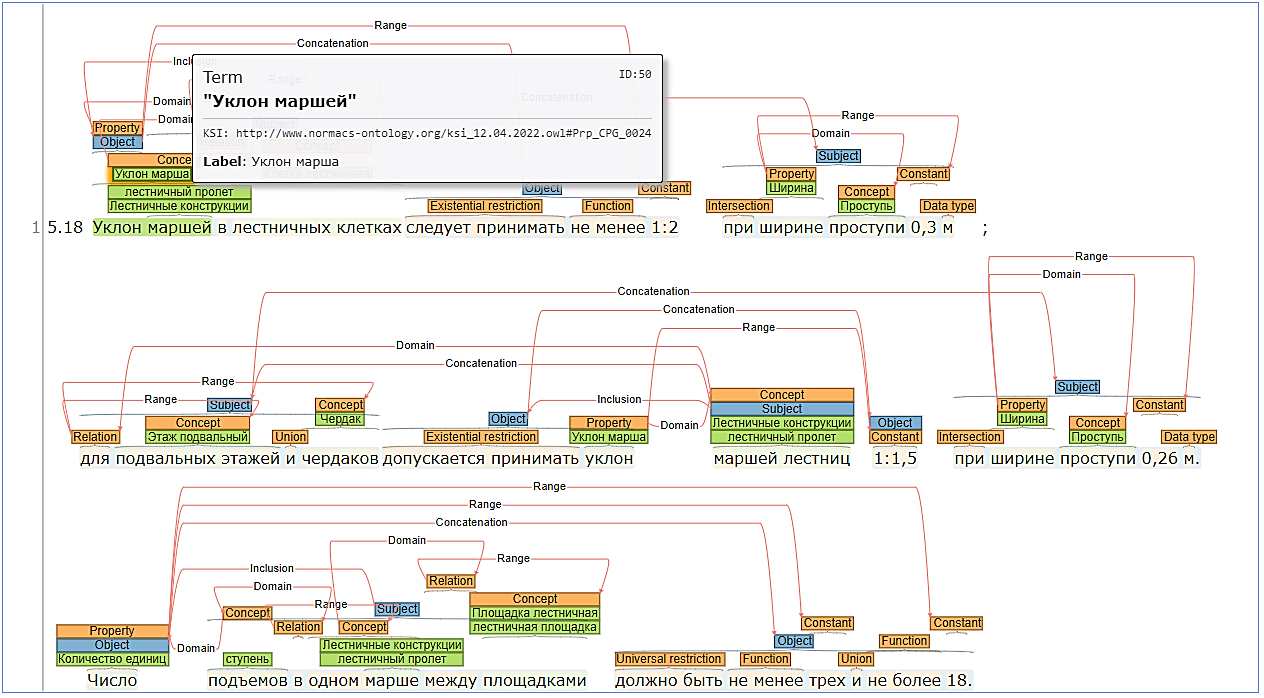
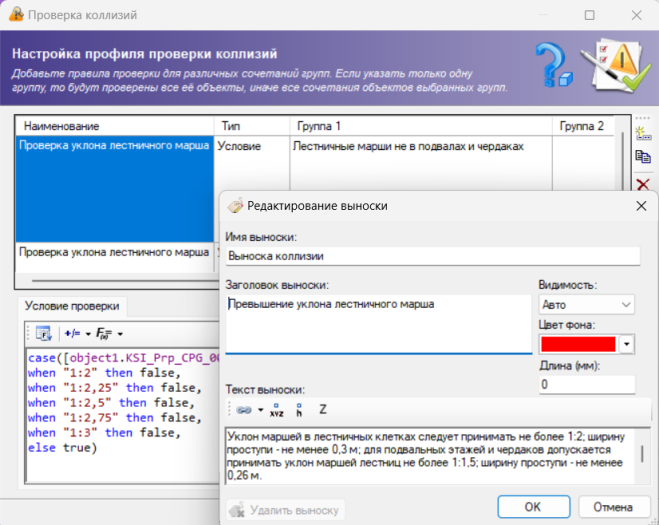
Параллельно разрабатывается инструмент, автоматизирующий разметку требования и позволяющий выполнить конвертацию текста в файл импорта профиля проверки на коллизии для программного комплекса CADLib Модель и Архив.
Проверка ИМ с помощью кодов КСИ
А теперь рассмотрим создание проверки на базе требования к устройству лестниц (рисунок 4).

Первое, что необходимо сделать, — это выделить из всего перечисленного короткие самостоятельные требования:
- #1 Уклон маршей в лестничных клетках следует принимать не более 1:2.
- #2 Ширину проступи следует принимать не менее 0,3 м.
- #3 Для подвальных этажей и чердаков допускается принимать уклон маршей лестниц не более 1:1,5.
- #4 Для подвальных этажей и чердаков допускается принимать ширину проступи не менее 0,26 м.
Причем требование #3 вносит исключение в #1, а #4 — в #2.
По идее было бы хорошо сперва проверить все уклоны маршей и ширину проступей, а затем перепроверить расположение найденных нарушений и снять ошибки с тех, что находятся в подвальных этажах и на чердаках. Но конкретно такой сценарий в программах, осуществляющих проверку ИМ, воспроизвести невозможно. Поэтому нам придется вносить изменения в структуру выделенных требований. И это первый пример, когда внешний фактор влияет на обработку текста.
Кроме того, требования #2 и #4 говорят о проступях, которые редко моделируются самостоятельными объектами, — чаще это параметр ступени или целого лестничного марша. И это тоже следует отразить в изменениях.
Получаем:
- #1 Уклон маршей (кроме подвальных этажей и чердаков) в лестничных клетках следует принимать не более 1:2.
- #2 Ширину проступи лестничных маршей (кроме подвальных этажей и чердаков) следует принимать не менее 0,3 м.
- #3 Для подвальных этажей и чердаков допускается принимать уклон маршей лестниц не более 1:1,5.
- #4 Для подвальных этажей и чердаков допускается принимать ширину проступи лестничных маршей не менее 0,26 м.
Далее надо определить параметры, которые будут отвечать за отбор объектов, и проверяемые атрибуты с допустимым пределом значений (рисунок 5).
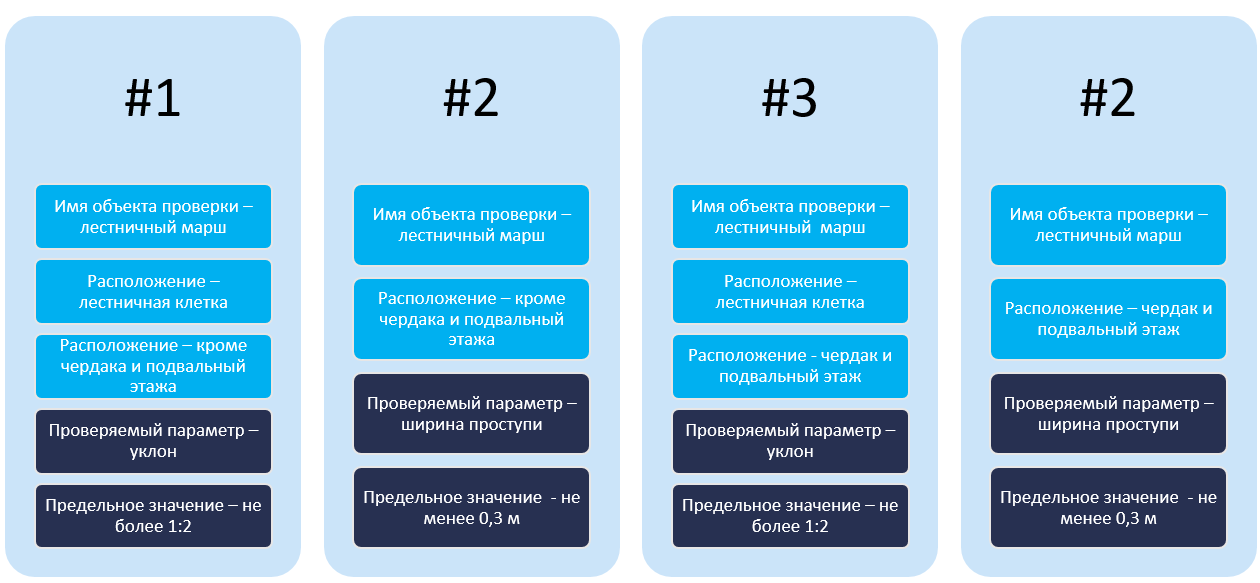
Затем надо сопоставить вышеперечисленные параметры с кодами КСИ:
- в таблице Com (Компоненты) отсутствует код для лестничных маршей. Есть только «Com>XSB: Лестничный пролет», причем «Лестничный марш» указан в синонимах наименования, что является спорным моментом, так как нормативные документы в принципе не содержат термина «Лестничный пролет» и сведений об альтернативных наименованиях.
Есть вариант использовать код из таблицы CPr (Ресурсы): «CPr>AEBA: Лестничный марш». Но в этом случае непонятно, как включить в проверку марши, замоделированные отдельными элементами (ступени, косоур, балка
- Код зоны «RZo>EAD010: Клетка лестничная»;
- Код параметра уклона «CPG_0027:Уклон марша»;
- Код параметра ширины проступи отсутствует в КСИ, а общий параметр ширины было бы использовать некорректно, поскольку ширина лестничного марша и ширина проступи — совершенно разные величины. В итоге был создан пользовательский параметр «XPGU_0004:Ширина проступи»;
- Код зоны «RZo>SB: Чердак»;
- Код зоны «RZo>STA: Подвал».
В тестовой ЦИМ выбранным объектам были назначены коды КСИ, используемые при проверке (рисунок 6).
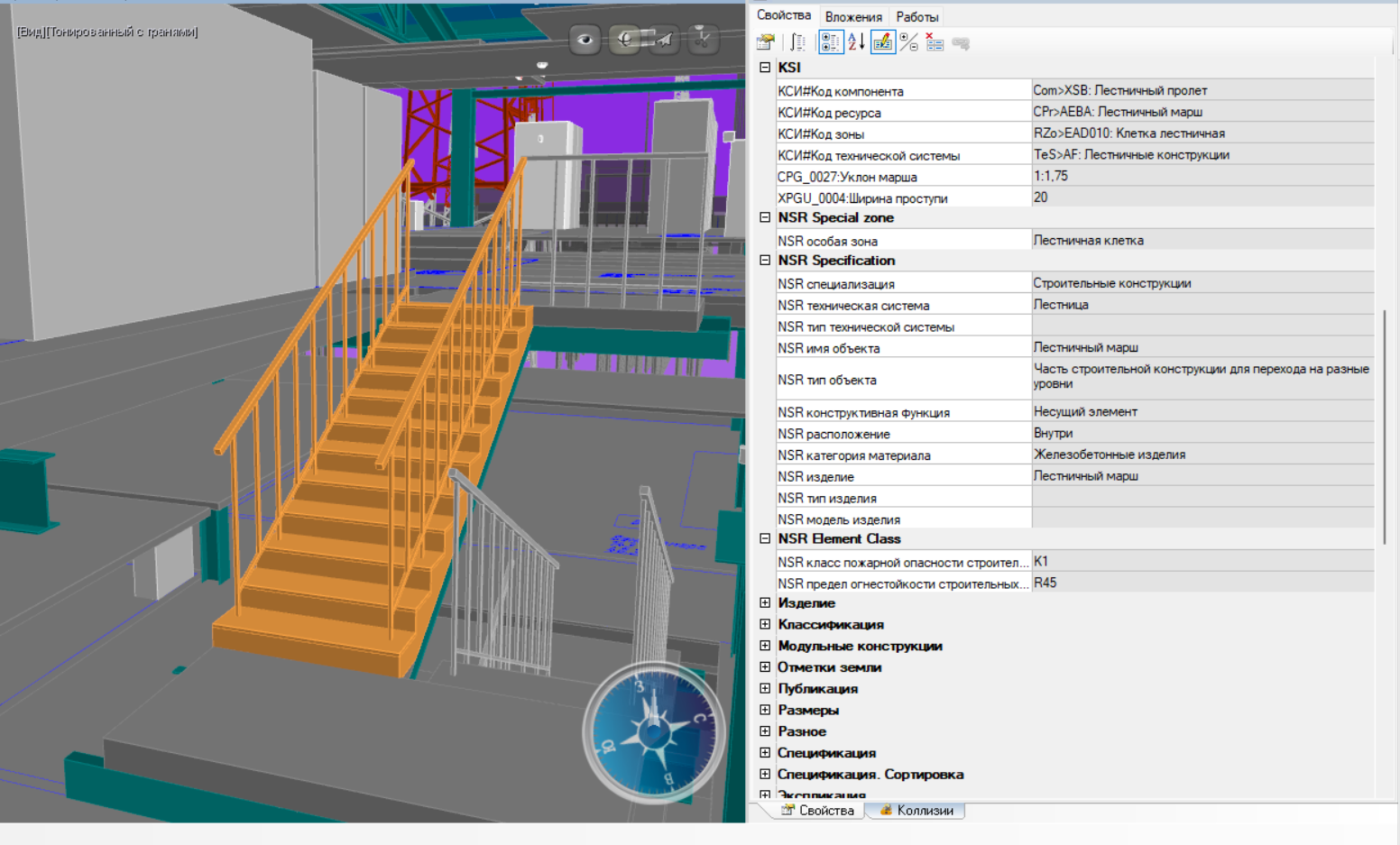
Справедливости ради следует отметить, что согласно методике применения КСИ объектам должен назначаться составной код. Но для наглядности на этапе эксперимента удобнее использовать коды, размещенные в отдельных параметрах.
Кроме того, коды зоны назначены этажам, которые присутствуют в модели в качестве структурных элементов.
Далее размеченные требования были сконвертированы в обменные форматы профилей проверки в программном комплексе CADLib Модель и Архив (рисунок 7).
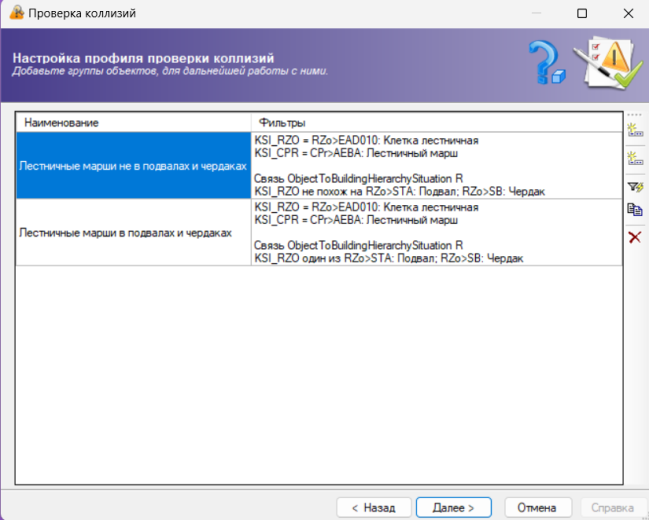
|
|
И благополучно найдены нарушения (рисунок 8).
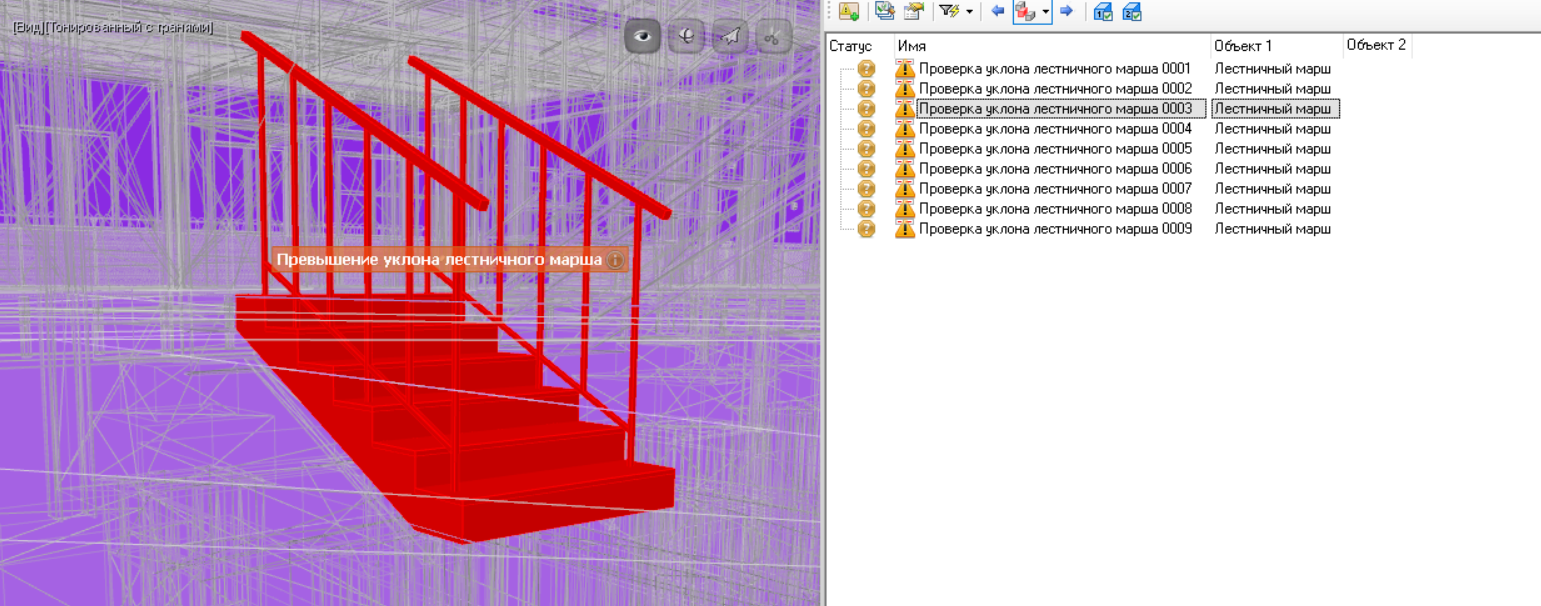
Даже на таком простом, на первый взгляд, примере наглядно видна проблематика рассматриваемой задачи. Это и вольная терминология, используемая, с одной стороны, авторами норм и стандартов, а с другой — разработчиками КСИ; и недосказанность, понятная человеку, но недоступная машине; и несоответствие смысловых единиц требования объектам ИМ, создаваемым на практике; и, наконец, исключения, которые могут вносить одни требования в другие.
Кроме того, при обработке норм и стандартов:
- встречаются условия, которые в принципе невозможно измерить с помощью программных средств;
- встречаются условия, которые сложно измерить по причине функциональных ограничений программы, в которой осуществляются проверки;
- встречаются условия, использование которых требует нестандартных решений или внесения изменений в текст;
- сами требования могут быть неоднозначными в интерпретации.
Таким образом приходится признать: отнюдь не все требования нормативных документов поддаются легкой и безболезненной автоматической конвертации в правила проверки. Безусловно, требуется контроль эксперта, что как раз и учтено в инструментах и решениях NSR Specification.
В планах на будущее программного продукта NSR Specification:
- разработка профилей проверок ЦИМ в рамках пилотных проектов для заказчиков, которая позволит создавать осязаемый результат, набираться опыта и копить базу примеров для будущей автоматизации;
- доработка требований к описанию объектов ЦИМ и синхронизация нашей схемы данных с КСИ;
- добавление профилей проверок ЦИМ к базе машиночитаемых требований NSR Specification, доступной широкому кругу пользователей.
Сейчас доступен веб-ресурс «NSR Specification Подсистема требований», где можно быстро найти требования из множества документов, относящиеся только к определенному коду КСИ или ОКС. В рамках внедрения возможна поставка в контур организаций как данной подсистемы, так и подсистем «NSR Specification Подсистема семантической разметки» и «NSR Specification Подсистема обсуждения проектов».
Развитие программного комплекса и исследования в области искусственного интеллекта продолжаются, авторы надеются, что технологии семантического анализа и алгоритмы методов обработки естественного языка (NLP) способны сделать человеческий труд по обработке текста норм и стандартов более эффективным, а достижение высоких целей цифровизации процесса проектирования — вполне реальным в обозримом будущем.
- SMART (Standards Machine Applicable, Readable and Transferable) — стандарты, применимые для машин, читаемые машинами и передаваемые на машины. ↑
- Требование — выраженное в виде текста, изображений, формул и таблиц правило, которое должно трактоваться однозначно, применяться в известных случаях, содержать все необходимые исходные данные и при этом не быть избыточным (то есть не содержать в себе других требований). ↑
- Машинопонимаемый контент — совокупность требований, изложенных в объектно-ориентированном формате в виде логического выражения. ↑
- В распоряжении
Правительства РФ от 31 октября 2022 года№ 3268 -р термины даны как «машиночитаемый и машинопонимаемый стандарт», термины «машиночитаемый» и «машинопонимаемый» контент введены авторами в рамках этой статьи. ↑